Distant Reading the VICE Source Code
Journal
2023-05-07
Basic Voyant Tools setup
- If you work on a corpus and change the settings, remember to !/guide/start-section-bookmarking-your-corpus to access it later again
- Running Voyant Tools locally isn’t strictly necessary, but it improved speed in my case
- Setup Voyant Server !/guide/server
- I Ran into problems on launching VoyantServer on macOS; had to give the Java Runtime Environment Full Disk Access and start the server via shell
- Copied all
.cand all.hfiles from thesrcfolder into a new Voyant project (ignore the import warning). This also means I flattened the hierarchy in which the files were organized. I believe this to be neglectable in the case of VICE - Deactivate !/guide/stopwords, since in code every word can have meaning and is not just syntactic glue
- Add !/guide/categories and colour-coded them
Stopwords and categories for C
Here is a list of relevant stopwords generated by ChatGPT or Github Codepilot, provided by Moritz Mähr.
- Data Types
- char , double , float , int , long , short , signed , unsigned , void , _Bool
- Control Flow Keywords
- break, continue, do, else, for, goto, if, return, switch, while
- Storage Class Keywords
- auto, extern, register, static, typedef
- Type Qualifiers
- const, restrict, volatile
- Other Keywords
- _Alignas, _Alignof, _Atomic, _Complex, _Generic, _Imaginary, _Noreturn, _Static_assert, _Thread_local
To look into
- Categories (Keywords, Comments etc.)
- Contexts word sequences: !/guide/collocatesgraph , !/guide/corpuscollocates , !/guide/contexts , !/guide/phrases , !/guide/wordtree
- !/guide/topics and !/guide/trends
2023-05-17
After a rather messy start with the complete corpus, I wanted to have a go at just the comments. I tried my luck with regex and search and replace, first in vscodium, then in a bash onliner (with find and sed) to remove everything that is not a comment. Spent a few hours on this problem without much luck, mainly because vscodium couldn’t handle search and replace and several thousand files. I reverted to working with python and asked ChatGPT to produce me a script that solved my problem…
My prompt “I need a python script that goes through a folder with files, searches through them with a regex pattern and copies the matches into new files” resulted in a proposition which I needed to tweak a bit to work as intended. That took me 20 minutes in the end.
Python script
Splits VICE source code into comments and code
I already had the regex pattern in place. After the clean-up, I loaded everything into a new corpus and started to play a bit. It indicates that I don’t have much experience with text mining, but at least it already seemed more meaningful. This new corpus, based just on the comment, will be the starting point for a later exploration.
2023-05-24
I worked on the python script to also remove the licence from the text files. Since they have been present in every document, they clogged up Voyant Tools with their presence. The script block in the former log entry is updated accordingly. Spinning up Voyant with this cleaned up corpus feels at least like a proper text.
Not advancing with reading the corpus through Voyant Tools. The comments are heavily segmented and include plenty of technical terms. Often the comments are brief and referential, respectively, again coded. Examples include what type a function is – peek, open, init, close, store, read, reset, and my favourite the “NO poke function”.
What style and what intent drives a comment? Of course brevity and precision, but many comments wouldn’t fit one or the other. Some comments indicate what should happen, or comment the process along the lines of code.
detect 35..42 track d64 image, determine image parameters.
Walk from 35 to 42, calculate expected image file size for each track,
and compare this with the size of the given image.
start at track 35
check if image matches “checkimage_tracks”
image file matches size-with-no-error-info
image file matches size-with-error-info
try next track (all tracks from 35 to 42 have 17 blocks)
we tried them all up to 42, none worked, image must be corrupt
Then again, other comments tell little stories.
HACK: if the image has an error map, and the “FDC” did not detect an
error in the GCR stream, use the error from the error map instead.
FIXME: what should really be done is encoding the errors from the
error map into the GCR stream. this is a lot more effort and will
give the exact same results, so i will leave it to someone else :)
There are also strong indications that different authors follow different comment styles and approaches.
Maybe I’ll research around VICE next to get a better picture. Since critical code analysis is an interpretative method, it “requires reading an object in its (post)human context through a particular critical lens.” (Marino, 2012, p. 15) Community, history, but also the embedded values and frame of reference will be important.
2023-06-07
- A large problem in reading source code as literary text is that it is not easy to sort in a linear way, which in turn makes it hard to generate meaningful patterns. Capturing thoughts on that in Source Code as Text
2023-06-12
Expanded python script to split into comments and into code files.
By reading through André Fachats insightful text on aspects of the VICE emulator I learned that the V in VICE stands for versatile. That means the emulator incorporates several different Commodore hardware configurations. I guess, this makes it even harder to process meaningful information through distant reading. A graph based approach would be interesting, but then it is definitely not a textual reading anymore.
2023-06-18
I followed my last insight and tried to have a look at the VICE source code corpus through the eyes of Gephi, which is a tool for network visualisations. I produced two new python scripts. The first script is attempting extracting the relations between the source code files by looking for #includes. The second extracts the relation between authors and on which files they worked.
Visualization of the two networks
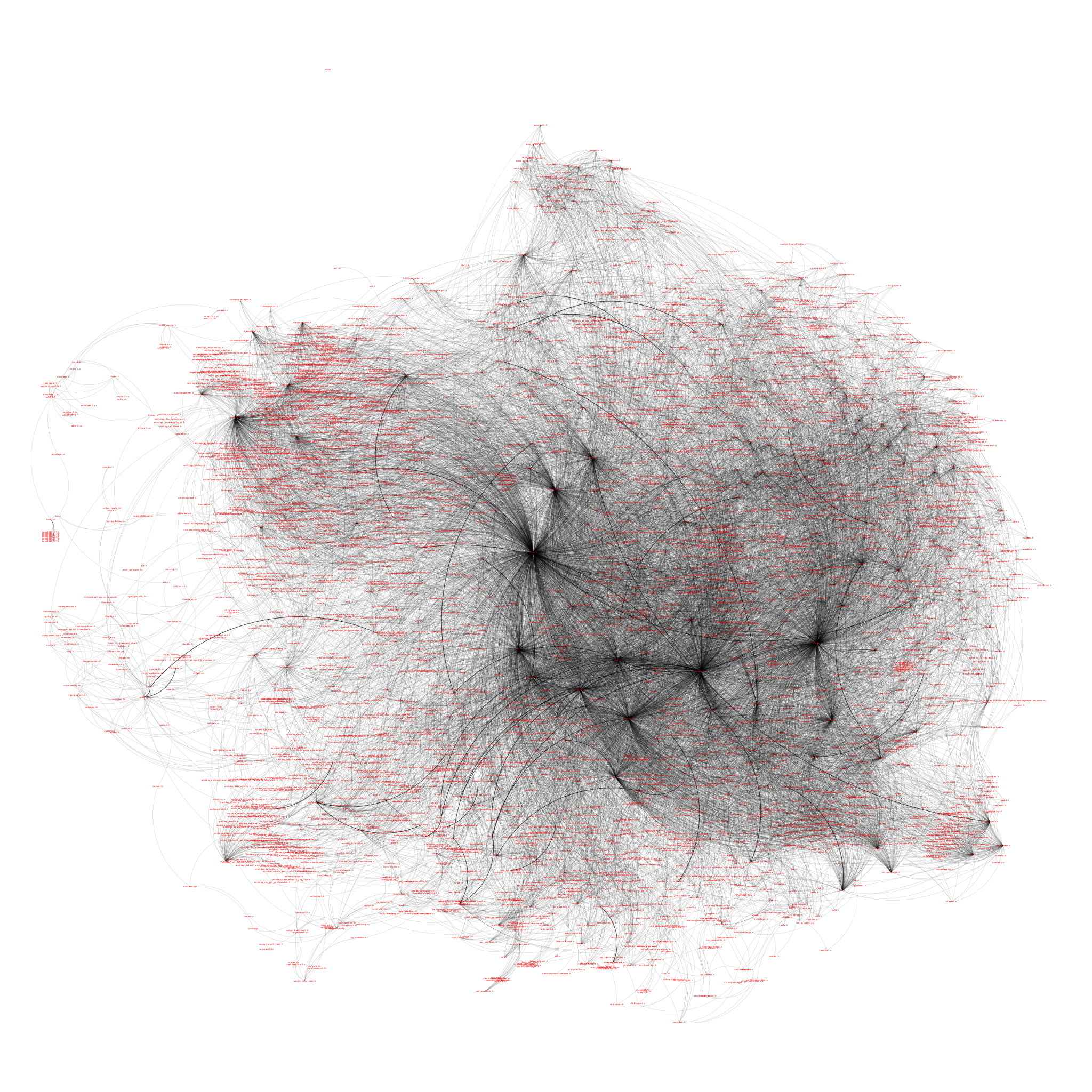
Relations between files
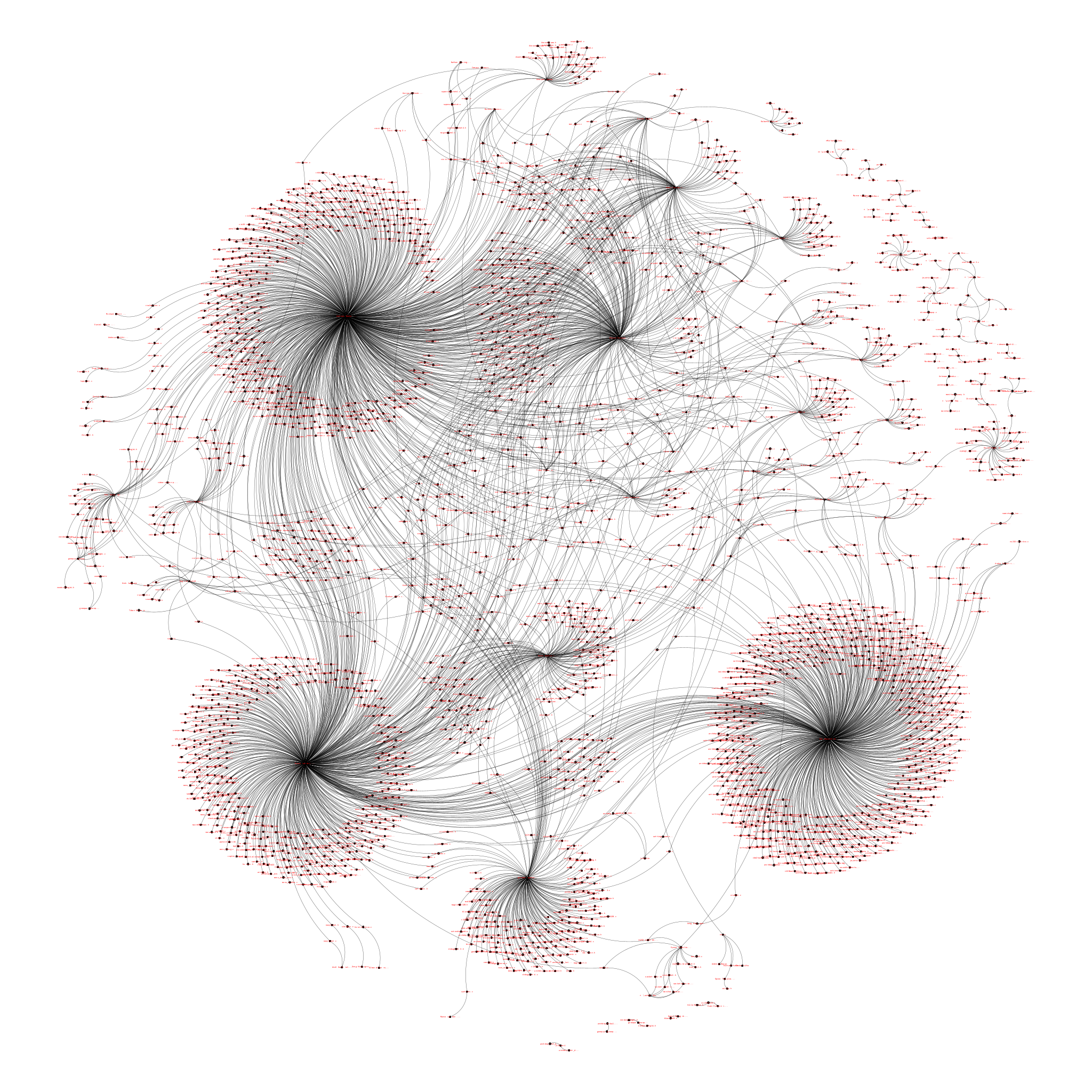
Relations between author and source files
Quick Insights
The network between the source files, through acts of #include, reveals a hot mess. There is no way of bringing this corpus into a linear order. There were 2839 nodes and, 19463 edges. Such a corpus needs to be treated as a hypertext, but I have no idea right now, how to extract meaningful distant readings from such a thing. Nevertheless, it confirmed my assumptions about the non-linearity of the source code. I probably should have thought of that earlier…
The authors networked had 2590 nodes and 3390 edges. In contrast to the source code files networked, this visualization leads to the clear insight, that just a handful of people developed the majority of the code base, with around five to ten key players. In a quick check, I could figure out that more than half of the key players are not listed as “current developers” any more. It is also the key players who collaborated on files, while also having many areas on their own. I believe a clustering by functional area within the VICE emulator could be interesting here.